With this blog post we would like to start a small series that will focus on sharding in MySQL. If you wonder, should you shard your data? At which point it is a necessity? What are the approaches to sharding the data? How to build the sharded environment? How to design it to minimize the impact to the database? If you are asking those questions, this blog series may be for you. Those are also questions we get from our customers, who are interested in our consulting services. Obviously, the exact implementation will differ based on the data structure, hardware and configuration constraints but such generic blogs should serve well to give a high level overview of how sharding may look like. Let’s start with some basics.
Scaling out MySQL
You are a new startup and you decided, as many others, to rely on MySQL as your primary database. It makes sense – it is a well known, reliable and fast database with a huge ecosystem and a large talent pool to hire from. You start with a small, highly available environment. Three node Galera cluster or, let’s say, asynchronous replication with a source node and one or more replicas. You have a loadbalancer or another way of tracing the replication topology. For asynchronous replication you may have an Orchestrator or some other tooling that will perform the failover when required. What are the options you have to scale out?
Load types in MySQL
There are two main types of load in MySQL – database performance can be CPU-bound or I/O-bound. In the first case we are talking about all the situations in which the CPU has been saturated. It can be a result of inefficient queries or just a sheer volume of them. It can also be triggered by some internal contentions in the database – internal spinning or context switches may also result in the CPU load.
Second type is the I/O-bound load. What it means is that the database is impacted by the volume of I/O operations. This may be a result of, again, queries that are inefficient and perform lots of disk scans. It can be triggered by the sheer volume of writes – INSERTs, UPDATEs, DELETEs that are executed against the database. It can also be induced by SELECT queries if the active data set does not fit in the memory and MySQL has to load data from disk to InnoDB buffer pool.
How to scale out MySQL?
As discussed above, there are two main types of load in MySQL. Let’s start with the CPU-bound load. What can be done about it? The first step, always, is to optimize the database configuration and queries. You always want to start with a performance audit to see what you can squeeze out of the existing setup. If the optimization efforts won’t bring good results, there are further options that we may want to consider.
Vertical scale out
First, vertical scaling. What vertical scaling means is, to put it simply, bigger the better. If you use instances with 8 vCPUs, you can change them to instances with 16 vCPUs. The most typical problem with such an approach is twofold. First, it’s expensive – larger instances usually come with a premium price tag. Second, you cannot scale vertically forever. Finally you will reach the size of an instance that you cannot increase further. FOr example, if we are talking about Amazon Web Services, you can get as many as 128 vCPUs on Intel-based instances or 192 vCPUs on AMD-based instances. Once you reach this level, you meet a road block – there’s no way forward to scale out vertically. Luckily, we have another option.
With I/O-bound load the situation is quite similar. Yes, we can use faster disks or add more disks into the disk array to make it perform better. We can increase the amount of provisioned IOPS assigned to our instances. One way or the other you’ll always hit the wall at some point. 256,000 IOPS is the magic number for AWS but in reality, as for every block device, network limits may also play a significant factor in disk performance. Outside of the cloud you will encounter limits in terms of hardware performance, size of the disk array you can use, network performance if you use SAN. There is just no way to scale out infinitely.
What is great is vertical scale out, as long as it is feasible, solves the problem no matter if we are talking about reads or writes. As we mentioned, the main issues with such an approach is it cannot be used indefinitely and throwing more vCPUs or pIOPS is definitely not a cheap approach to the performance.
Scaling reads through horizontal scale out
That would be a horizontal scale out. Instead of increasing the size of an instance we can also add more instances of the same size. Sure, it is not as easy as scaling up the instance size – if you add more CPU cores, you don’t have to do anything else and your application or database will just use the resources it needs – roughly speaking. In reality more cores means more internal contention which may require some reconfiguration on both database and Linux’s side to be able to use more resources efficiently. On the other hand, adding more nodes requires more thinking and planning. How am I going to use those nodes? How can I send a chunk of traffic to the newly added nodes? How am I supposed to tackle the problems that replication introduces – replication lag, read-after-write inconsistency and many others? Luckily, there are many known ways in which you can ensure that you will be able to benefit from more nodes. In the perfect world we should be able to use all of the nodes to their fullest potential. What it means is, if we run a 3 node cluster on 60% CPU capacity, by adding 2 more nodes we should be able to reduce the CPU utilization to ~36% per node. The math behind is simple – 3 nodes multiplied by 60% is 180% of total load – such load may, barely, be sustained by two nodes – that would make it 90% load on each. If we add two more nodes, this will result in a 180% / 5 split which is 36%. We would expect that all nodes will be utilizing up to 36% of the CPU resources giving us a room for growth and ability to sustain a failure of one node even easier. If we’ll need to scale out our setup further, we can add more nodes to the mix and distribute your queries across them all.
When it comes to the I/O scaling, the situation is similar. As long as the I/O load is created by SELECT queries, splitting them across more instances will reduce the load on every node in the cluster, so, in the perfect world, full of spherical reads, we can scale out the clusters quite easily by adding more nodes. Unfortunately, the writes do exist.
How to scale out writes?
In the not-so-perfect world that we live in, we want to appoint a writer node in Galera cluster or we have to pick the source node in the asynchronous replication setup. Such a node will be handling all of the write traffic. Yes, by adding replicas or Galera nodes we can scale out reads. If we suffer from the load caused by SELECT queries, we can try to distribute them across multiple nodes. The more significant problem will be to deal with write-related performance issues. Putting MySQL NDB Cluster aside, every database solution on MySQL has one assumption – dataset is identical across all nodes. What it means is that every Galera node, InnoDB Cluster node or every replica will contain exactly the same data as every other node in the cluster or the source node for asynchronous replication deployments. Keeping this in mind, it should be clear to understand that there’s no way to scale out writes. No matter what you do, every write will have to happen on every node in the cluster or every replica. Yes, some solutions like Galera Cluster allow to write to multiple nodes at the same time but it is not the way to scale out writes.


If you write anything to node A, this will have to be distributed to nodes B and C. If you write something to node B, it will be distributed across other nodes as well:


The same situation applies if we execute any write towards node C:


As you can see, no matter where the write was executed, it ended up on all of the Galera nodes. One can argue that with mechanisms like multiple write threads, group commits and such there is some performance gain by parallelizing the writes that happened on multiple nodes, but this is not the write scalability that we are looking for. We look for an option to scale by the factor of X depending on the number of nodes added. No existing solution in the MySQL ecosystem (again, putting MySQL NDB Cluster aside) can promise us that.
Another challenge database administrators may face is something as simple as the data growth. We all start with a small dataset but it grows with time. Stakeholders like to keep historical data for analytical purposes, product develops and increases in size and features causing the database to grow. Performance aside, this may cause a burden on the day to day operations. Queries may be slower but schema changes will be slower as well. A simple operation of adding a column, something that originally took a couple of minutes, may start taking hours and then days. Adding an index to speed up a query may become a significant burden on the operations team. What’s worse, this slows down the development of the application. Developers now have to wait hours or even days before their feature can be implemented only because the schema changes are the bottleneck. With time the database may become a huge, unmanageable monstrosity.
What is sharding?
When you end up in a situation like this, or, ideally, earlier, the only available solution is to split the dataset into multiple parts. This is, pretty much, what we mean by sharding. What you want to achieve is to split the data into multiple shards (how – it depends on the data, we’ll get there later) and create multiple highly available clusters that store those shards. You will also need a way to identify which shards contain which data – there are a couple of methods that can be applied here. As a result, the dataset will be split as well as the write workload.
Let’s say we have 2TB dataset and around 10k INSERTs per second:

If we will split the dataset evenly across five shards, we will end up with five clusters with more reasonable load and dataset size:
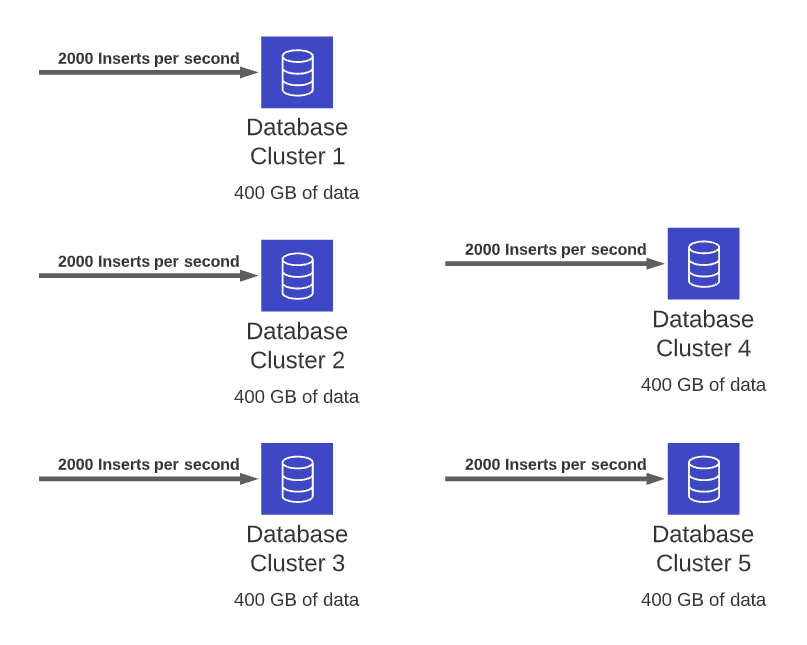
2000 INSERTs per second and 400GB of data.
Why do we want to shard the MySQL database?
So, why would you want to shard your database? Two main reasons: either the sheer amount of writes impacts the database performance (for example, replicas cannot keep up with the source for longer period of time) or the size of the data makes it hard to operate such cluster – backups and restores are taking their sweet time, making it impossible to meet your Recovery Time Objective, schema changes are taking ages, delaying the deployment of the new code and, eventually, becoming the bottleneck. Those are the most common reasons why organizations decide it’s time to shard their data.
Another question, which may lead to an interesting discussion, is when should we shard the database? Is this something we should consider as a part of the initial design? There are many takes on this but we would not recommend starting the database design process with sharding the database. Of course, there are cases where you know that in the known, short period of time you will reach the limits of a typical database deployment and you will have to implement sharding. Majority of the time this will not be required. Keep in mind that sharding comes with a significant increase of the operational complexity. In our example, every schema change has to be applied five times, in every shard. You would have to figure out how to ensure that the application knows where to connect to retrieve the particular rows. Sharding also requires its own maintenance – data, after some time, may have to be redistributed to ensure that the load is split more or less evenly across the shards. It is definitely not something that comes without a price tag in terms of the operational complexity and overhead. Keep in mind that, even if you would love to, majority of startups will not reach the terabyte scale and they will be perfectly fine with standard deployments. Optimized MySQL can really get you quite far.
If you are interested in this topic, please bear with us as we will publish more related content. In the next blog post we will continue with a bit of theory and we’ll talk about different approaches one may have when it comes to sharding. If you would like to share your experience around sharding, we’d love to hear from you – you can use the comment section under the blog post.
